















TeamCity Integration for JIRA breaks into Enterprise!

Not long time ago Atlassian announced release of Enterprise solution – JIRA Data Center. This solution was designed as a high availability and top performance platform for large instances hosted in a dedicated data center.
JIRA Data Center provides you with uninterrupted access to critical services, distributes the load proportionally across the nodes and saves you from any unexpected hardware failures and data losses. Other benefits include a capability to route the appropriate applications to the specific node within the cluster and add new nodes in the real-time mode.
We have being developing add-ons for JIRA for several years, and like Atlassian understand the necessity to adjust our products to requirements of enterprise customers. After the long-lasting development, enhancement and optimization we are proud to say that the TeamCity Integration for JIRA add-on has been significantly improved to meet actual needs of the most demanding enterprise users.
JIRA Data Center
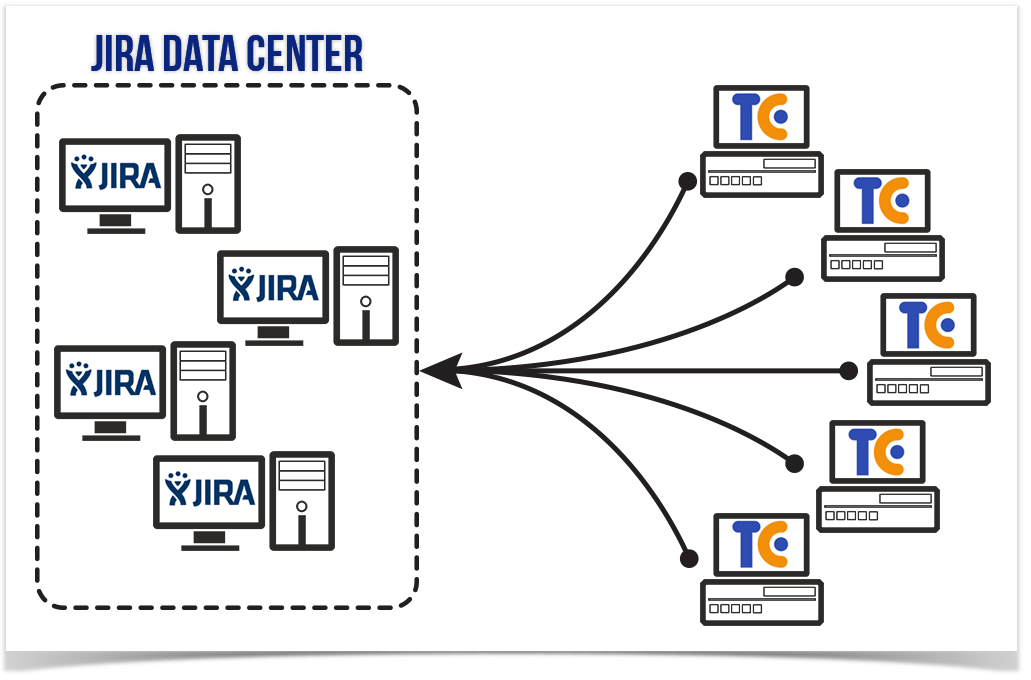
Starting from TeamCity Integration for JIRA 1.7.3 we added support for JIRA Data Center. Enterprise customers usually have complex infrastructure comprised of multiple TeamCity servers and a great number of users working with JIRA and fetching data from continuous integration servers. This stipulates high accessibility and instant response of the system that are available in JIRA Data Center.
Support for Multiple TeamCity Servers
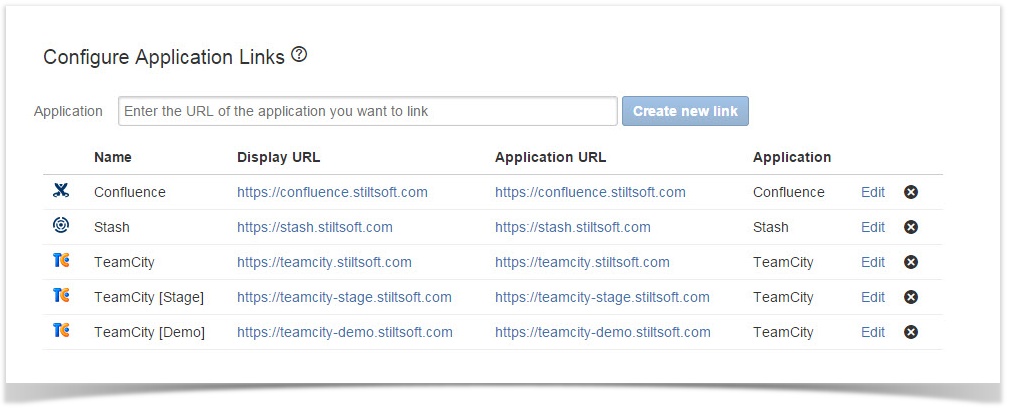
Enterprise customers usually have several TeamCity servers, which data about builds should be available in one place – in JIRA. Now the add-on allows you to view information about builds from multiple TeamCity servers within the associated JIRA issue and see availability of build agents per each server. You can connect as many as needed TeamCity servers to your JIRA just by adding the corresponding application links.
Persistent Data Storage
Some customers may also have TeamCity servers storing millions of builds. This fact affects availability of data in JIRA after its restart or update of the add-on. This can be achieved only through maximally quick data indexation and rapid data access to the requested information. The persistent storage for TeamCity data addresses all these issues and lets you always get quick access and maximal data availability after the scheduled maintenance work.
Indexation Optimization
TeamCity servers storing millions of builds can be slow due to large data amounts and can be even inaccessible because of the periodical clean-up. The continuous integration server may also store some abnormal builds with up to 10,000 commits and requests, which comprise two-gigabyte response from TeamCity server during data indexing.
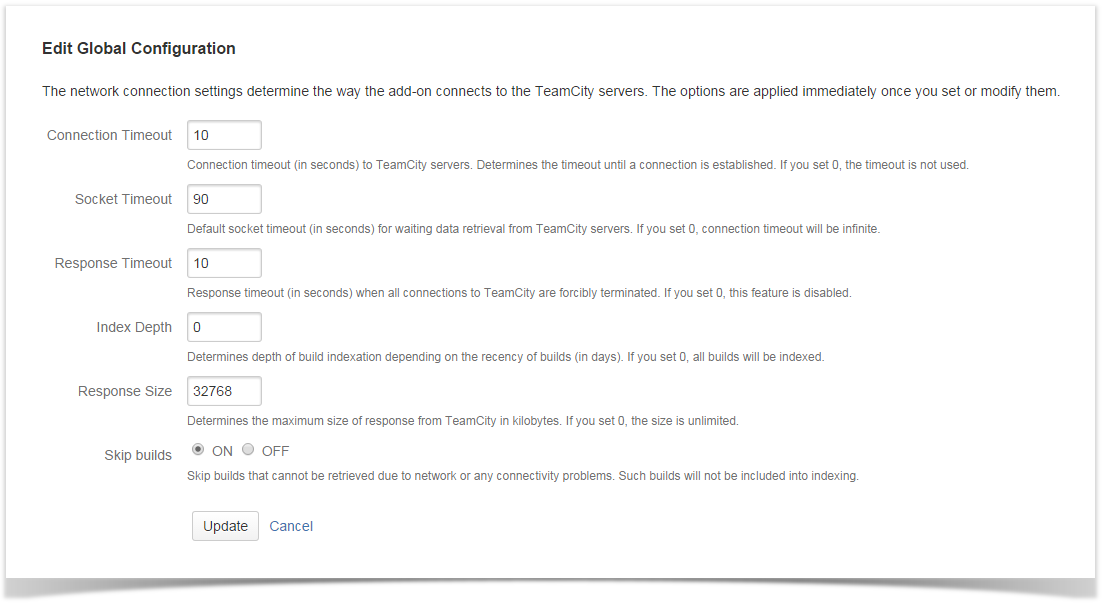
That’s why the add-on has received several options, such as Response Timeout, Socket Timeout, Connection Timeout that allow you to adjust data indexation and speed up the entire process from large TeamCity Servers. The three other options – Index Depth, Response Size and Skip Builds – allow you to limit depth of TeamCity data indexation and better handle abnormal builds with a capability to skip them from the indexing.
We hope that you will like the updated version of TeamCity Integration for JIRA. If you still have any questions or encounter any issues, feel free to contact us at any time.





