Pricing Adjustments for TeamCity Integration for Jira
June 30, 2022
#News
4 min
We would like to inform our community and the customers of the TeamCity for Jira Integration app of the upcoming price changes that will affect all hostings (Cloud, Server, and Data Center).
Since the first release of the app, we have extensively invested in the development of new features, provision of timely and effective support, and, of course, collaboration with you on improvements and adjustments within the app.
Our operational costs have greatly increased since that time, and at the moment we are heavily developing the Data Center infrastructure to ensure the reliability and high performance of our app under any circumstances.
Over the years, we were working to improve services for you and provide the best quality for your satisfaction. Thus, we’ve decided to normalize the existing prices and, in particular, make the Cloud version of the app more cost-effective.
For all hostings, the price change will go into effect on August 1, 2022. Below are the new pricing models.
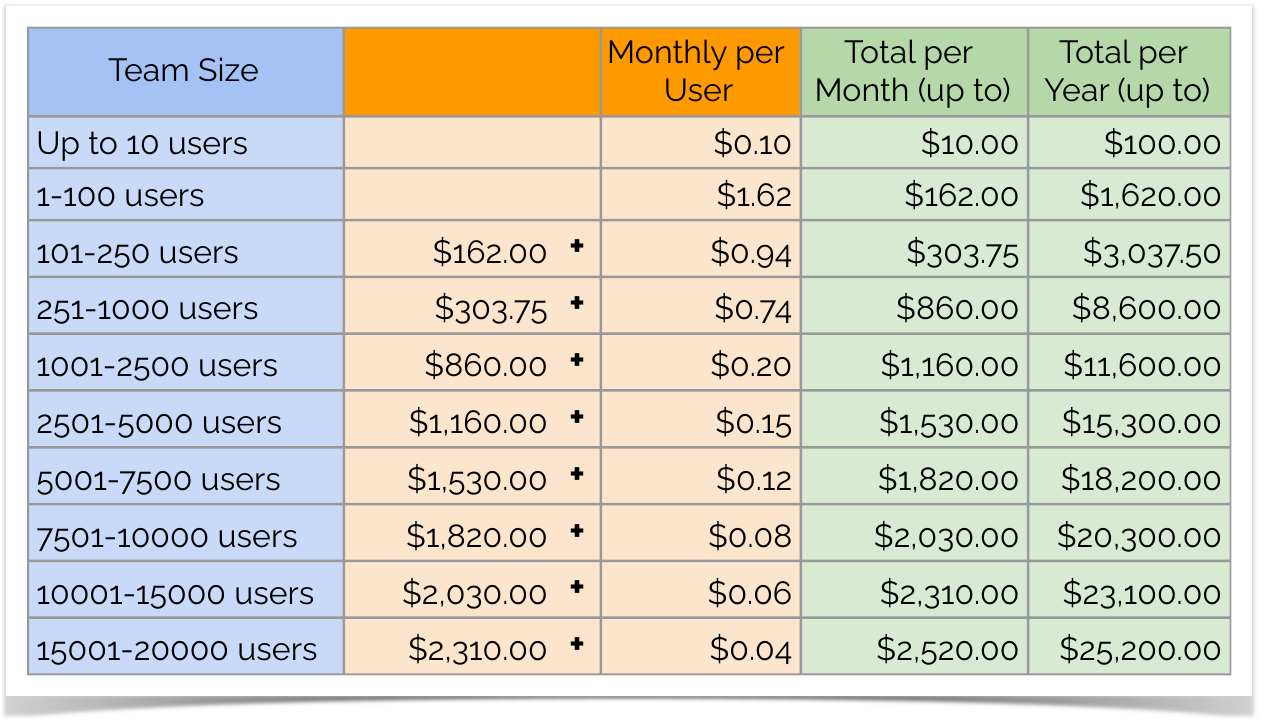
Cloud Pricing
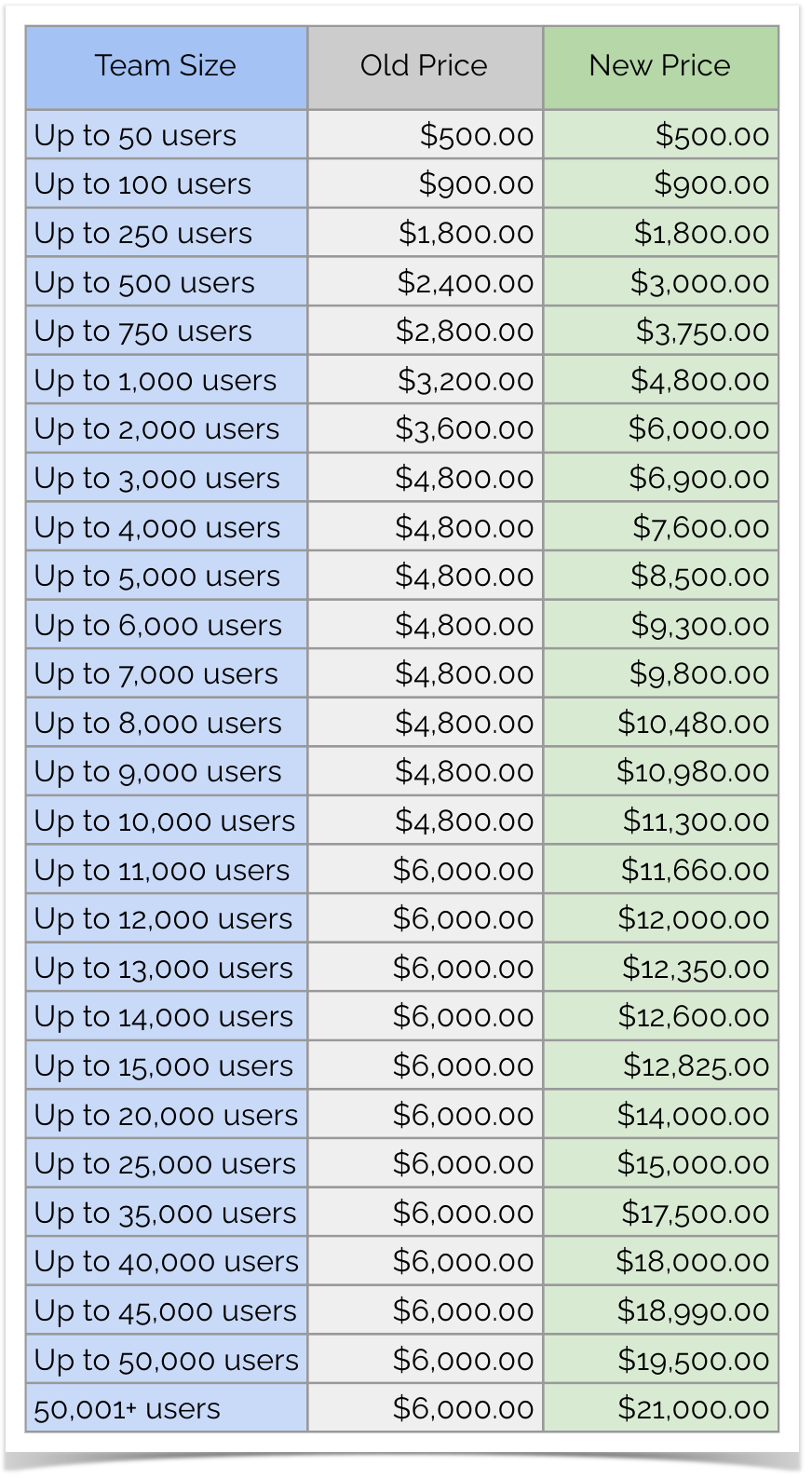
Data Center Pricing
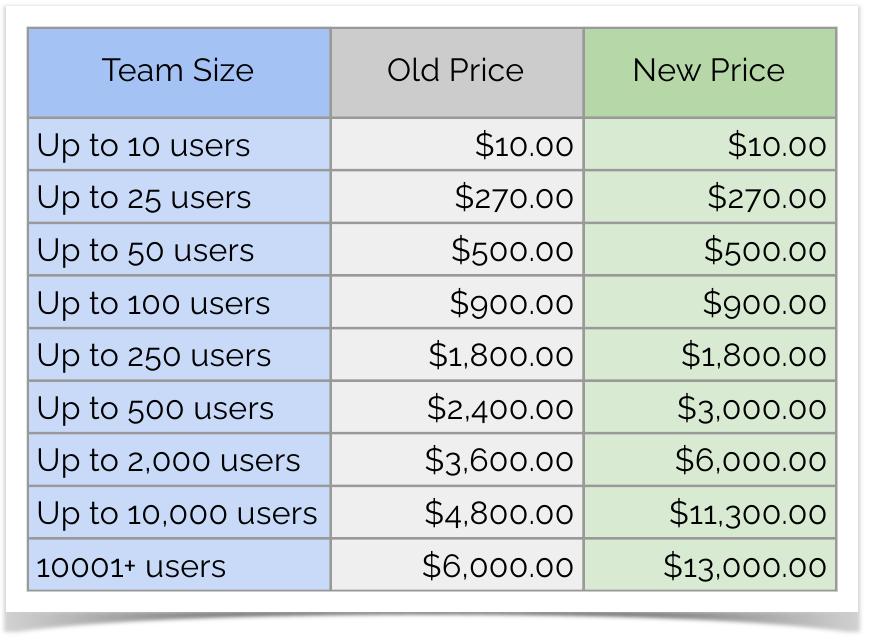
Server Pricing
Buy at today’s price
You can buy TeamCity for Jira Integration at the current price tillAugust 1, 2022. To save up even more, go with 2 or 3-year licenses — the price will remain the same for the whole maintenance period.
But even after August 1, 2022, existing customers with commercial licenses get a 60-day grandfathering period (till September 30, 2022), so you’ll have 60 days more to renew your license for the old price.
Have questions?
Please, feel free to contact us if you have any questions or need our assistance.
Subscribe for monthly updates on how to get the most out of Atlassian products.
Thank you for signing up
for our newsletter!
You will be the first to know about fresh content, releases,
and special projects.
Stay tuned.
Connect your Bitbucket to the TeamCity CI/CD server with TeamCity Integration for Bitbucket to run builds right from Bitbucket in one click, view build results, logs and artifacts right next to your code, and never lose time switching.
Atlassian JIRA has become, probably, the most popular bug tracker solution. It’s not surprising because it has a powerful set of features, flexible configuration and can be integrated with a variety of other solutions (especially developed by Atlassian). JIRA allows you to create different solutions for different tasks. It can be used for tracking simple home or family tasks (with a 10-user license that costs only $10), it can be also used for building a full-fledged enterprise task management and bug tracking solution with service desk. JIRA, starting from version 7, represents a platform for different applications. At the moment, there are three applications:
– JIRA Core – basic version of JIRA for tracking the tasks in the simple projects
– JIRA Software – old good JIRA that we know – with all its essentilal capabilities, including Kanban and Scrum
– JIRA Service Desk – service desk solution by Atlassian based on JIRA
TeamCity – one of the common and well-proven CI-solutions from JetBrains. It can be used by small teams of developers (there is a free version of TeamCity for small instances), but it also can be used as an enterprise CI-solution for the large companies. TeamCity allows you to automate build, test and deploy workflows.
We’re using in StiltSoft both JIRA and TeamCity for a development process. We’re updating our JIRA and TeamCity instances every time when a new version is available and we haven’t had any problems yet. JIRA 7 was released by Atlassian last year, and now JetBrains team is preparing TeamCity 10 to release (EAP already available). Let’s sort out what’s new in TeamCity 10.
Get Мaximum from TeamCity Integration through REST API
November 12, 2015
#Integration#How To#Jira
27 min
Connect your Bitbucket to the TeamCity CI/CD server with TeamCity Integration for Bitbucket to run builds right from Bitbucket in one click, view build results, logs and artifacts right next to your code, and never lose time switching.
Working in a team is a great challenge when you need close collaboration between different people of different occupations and specializations. This becomes a real pain when members of a team do not have direct communication or communication is complicated with external factors. Here come special collaboration platforms that leverage the gap between people and create a single environment for peer-to-peer interaction and efficient knowledge or information sharing.
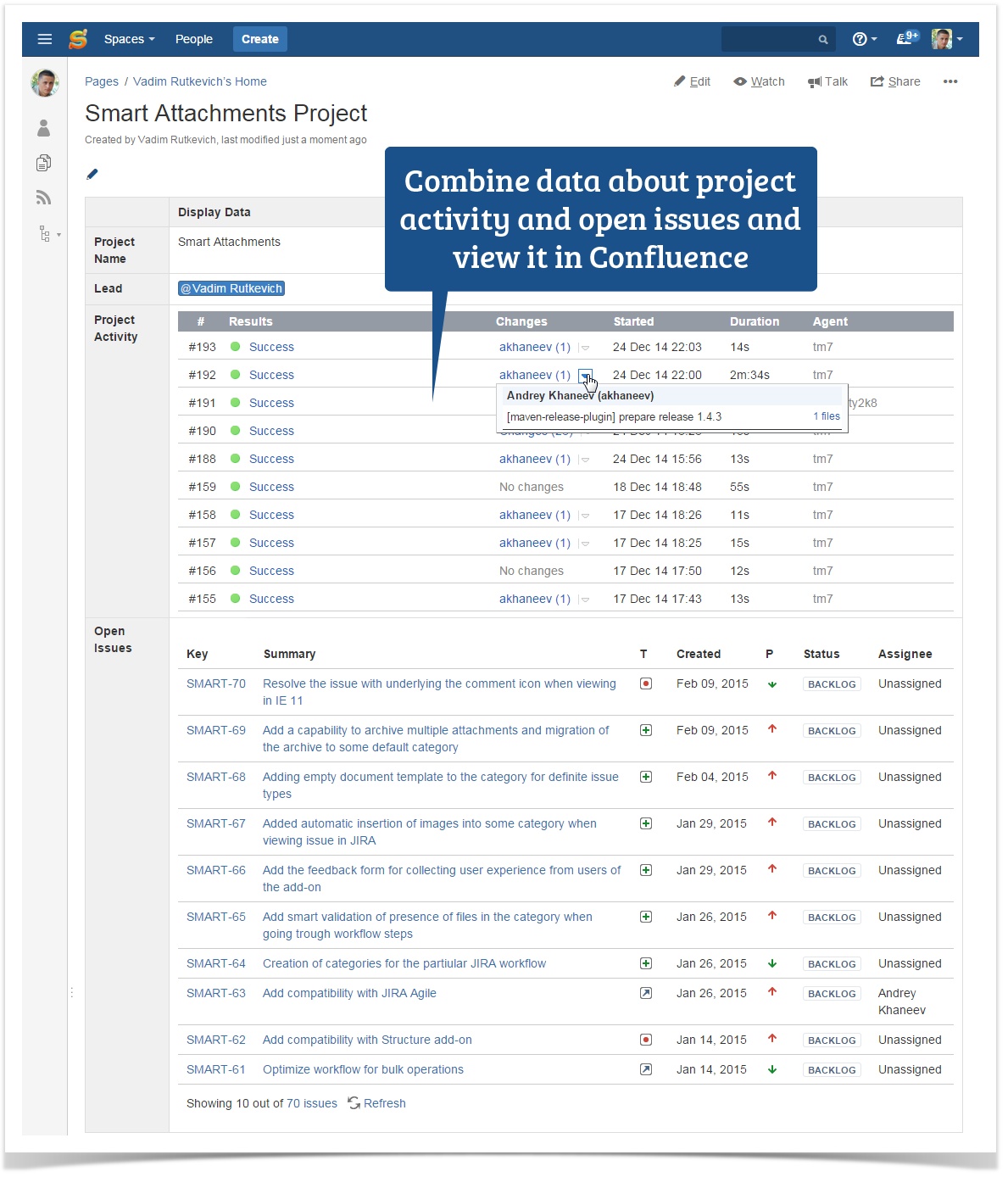
Today we will try to review an environment of TeamCity, JIRA and Confluence integrated into a single ecosystem for quick and easy data retrieval about builds and agents from TeamCity.
So what capabilities does this integration offer to the team of software developers? First of all, Confluence can be used as a collaboration platform listing the latest builds within the appropriate project and configuration. Project Managers and Team Leads can be always aware of the progress on the project and track the current activity on project development. JIRA can be used by developers and quality assurance engineers. Developers can track progress on issues and tasks, and quality assurance engineers can track the completion of development and proceed to testing of functionality.
TeamCity is already bundled with JIRA integration capabilities, but Atlassian JIRA does not have a native tool that can fetch build data and show it in JIRA issues, the same is true and for Confluence. The solution from StiltSoft team allows you to establish full-fledged integration between TeamCity, JIRA and Confluence, in addition to standard integration from JetBrains team available in Teamcity.
In our blog post we will show how you can create tools for fetching data from TeamCity via Rest API and showing this build data in some application.
Connecting to TeamCity Server
TeamCity provides REST API, which powerful capabilities can be used for fetching various data from TeamCity server. You need to send a HTTP request to REST API to fetch the required piece of TeamCity data. In order to get the requested piece of data you need to authorize on the server through one of the following ways:
Basic HTTP Authentication – you need to provide the appropriate TeamCity username and password with the request. In this case, you need to include ‘httpAuth’ into your GET request: http://teamcity-server/httpAuth/app/rest/builds.
Once your request has been processed, TeamCity server will return a piece of XML data, which you can further parse and output into your application.
Fetch Useful Build Data
First of all, TeamCity server stores a lot of build data, which is the point of interest #1 for you. Build data contains a lot of useful information about builds, their status, time for execution, completion status of tests and related issues in the issue tracking system. The best way is to fetch builds in batches – 20 or 50 builds per batch. You can use the following request to REST API of TeamCity server:
If you want to find out the related issues, you can perform an additional request which fetches information about the related issues in the issue tracker (for example, YouTrack or JIRA):
You can use the received project key and issue number for mapping to the particular issue in the issue tracking system.
Quality assurance engineers can easily monitor the status of each issue and can instantly proceed to functionality testing once the corresponding build with the fix is complete. So they needn’t wait for the development team when someone will resolve this issue in the issue tracking system.
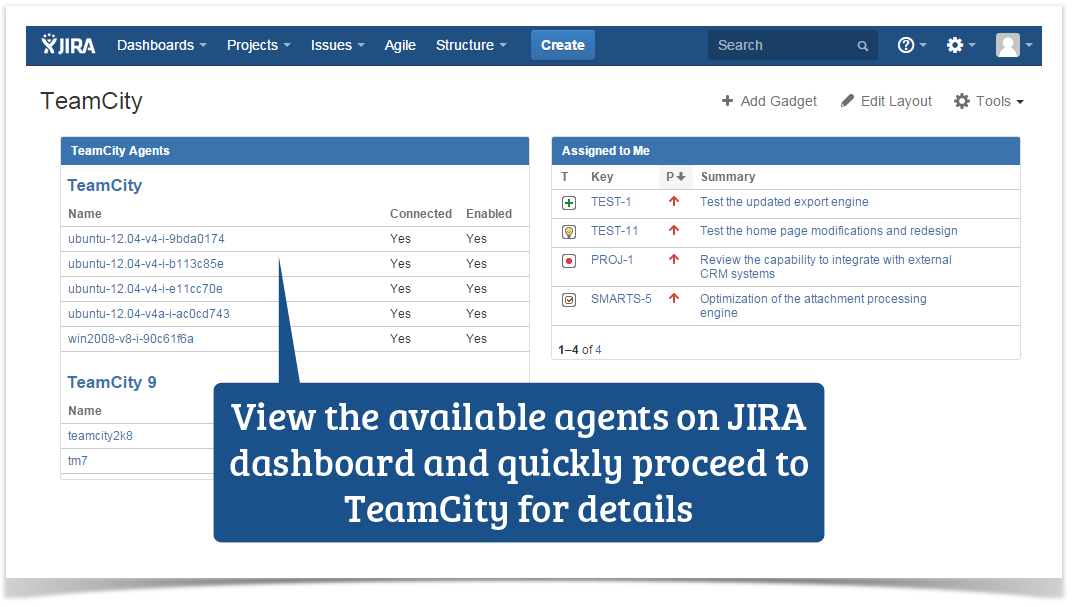
Find Out Available TeamCity Agents
You can also retrieve information about build agents and get the list of the currently active agents. This can be useful for the quality assurance engineer and developers to track availability of the specific build agent at the definite period of time. You can make the following request to display the list of available build agents:
Developers can easily view which build agents are currently in use by other projects and start building the project with another agent. The list of agents can be shown as a gadget on JIRA dashboard or placed as a macro on some Confluence page.
Optionally, you can also get information about the agent pools. Agent pool is a separate group of build agents that are assigned to the specific project for running builds. Any project can be assigned to multiple agent pools. Each build agent can be only assigned to one agent pool. You can run project builds only on build agents from pools assigned to the project. By default, all newly authorized agents are included into the Default pool. Agent pools allow you to bind specific agents to specific projects.
The XML output will include the following information:
project name
parent project (if applicable for the current project)
list of the latest build types of the project
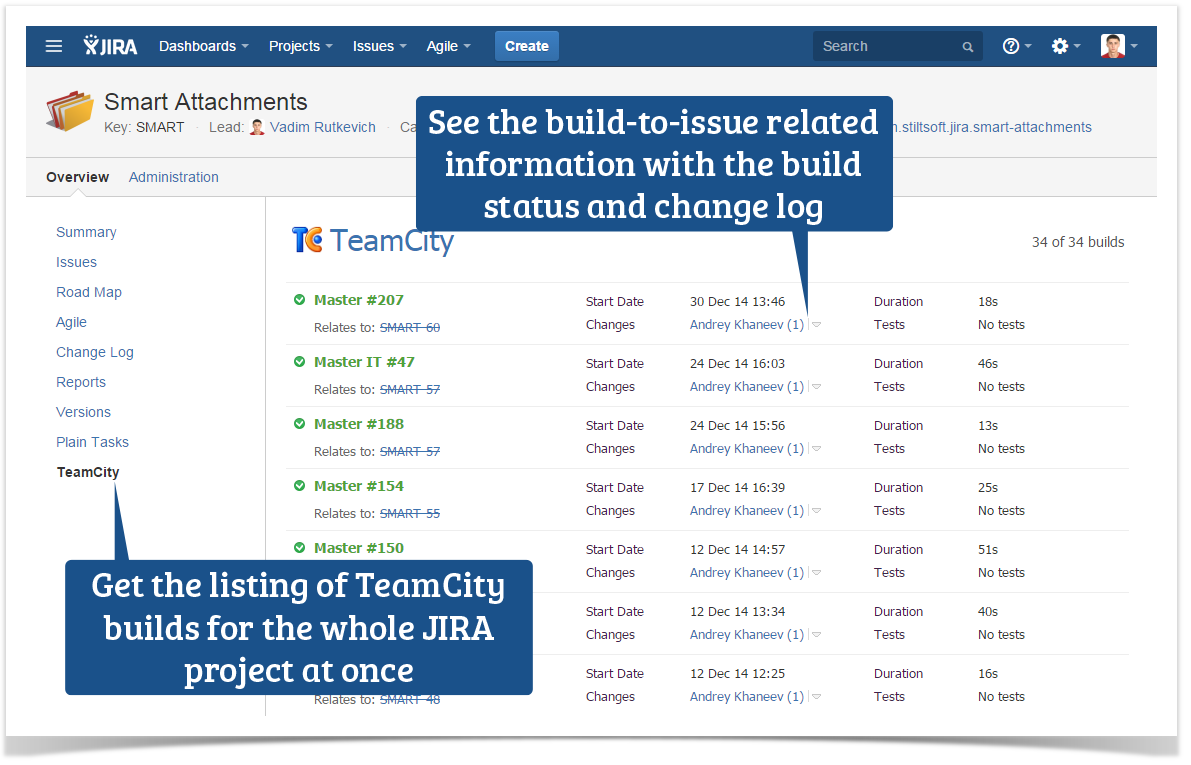
project description
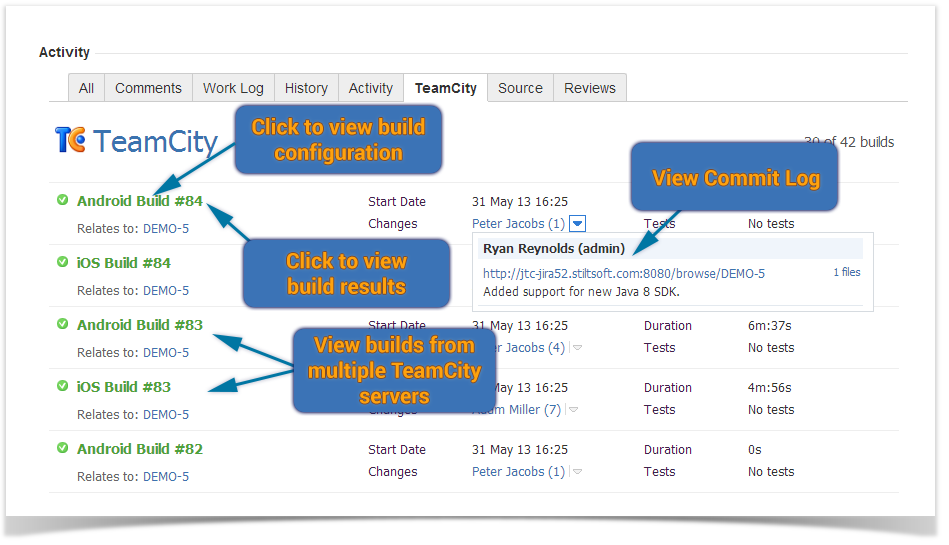
The project manager or team lead can get a simple picture of the project development in JIRA. The project will show the listing of builds and their relations to the created JIRA issues.
Alternatively, the project manager can use a macro on Confluence page and view the committed code changes per branch.
Results
REST API of TeamCity is a powerful and rich-in-features interface for getting build data and showing it in your application or system. It provides simple and easy-to-use requests for fetching data from TeamCity server, and even beginners can quickly start using it for building their custom solutions. Besides retrieving data from TeamCity server, you can also update or delete build data depending on the complexity and requirements of your project.
TeamCity Integration for JIRA breaks into Enterprise!
November 26, 2014
#Jira#Integration
6 min
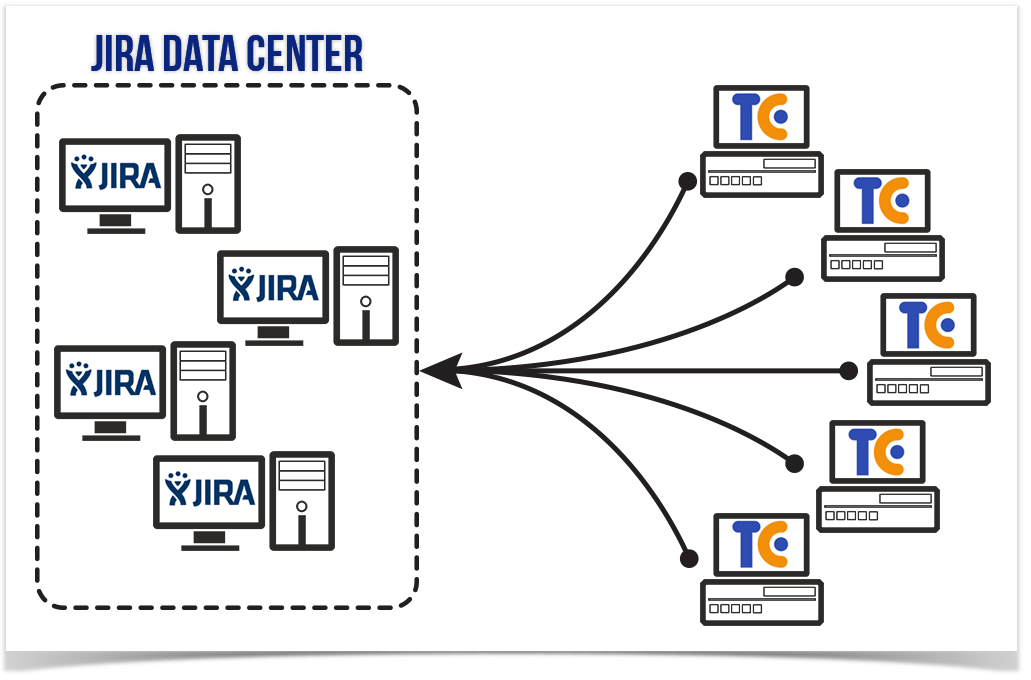
Not long time ago Atlassian announced release of Enterprise solution – JIRA Data Center. This solution was designed as a high availability and top performance platform for large instances hosted in a dedicated data center.
JIRA Data Center provides you with uninterrupted access to critical services, distributes the load proportionally across the nodes and saves you from any unexpected hardware failures and data losses. Other benefits include a capability to route the appropriate applications to the specific node within the cluster and add new nodes in the real-time mode.
We have being developing add-ons for JIRA for several years, and like Atlassian understand the necessity to adjust our products to requirements of enterprise customers. After the long-lasting development, enhancement and optimization we are proud to say that the TeamCity Integration for JIRA add-on has been significantly improved to meet actual needs of the most demanding enterprise users.
JIRA Data Center
Starting from TeamCity Integration for JIRA 1.7.3 we added support for JIRA Data Center. Enterprise customers usually have complex infrastructure comprised of multiple TeamCity servers and a great number of users working with JIRA and fetching data from continuous integration servers. This stipulates high accessibility and instant response of the system that are available in JIRA Data Center.
Support for Multiple TeamCity Servers
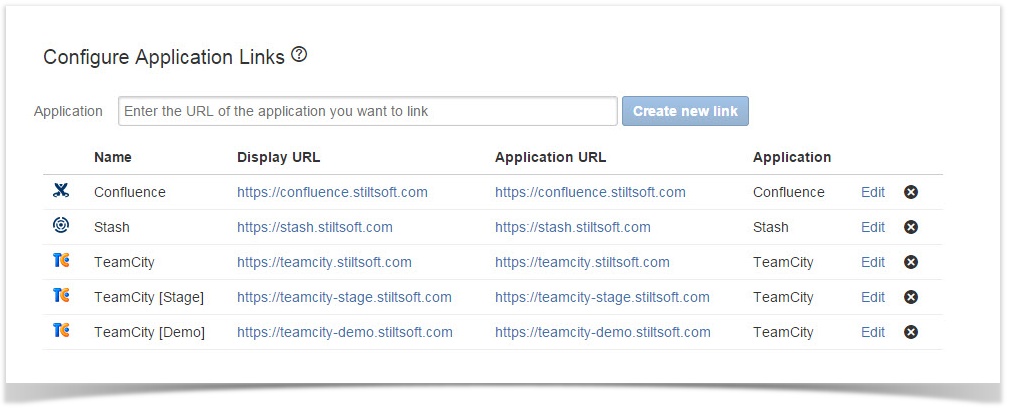
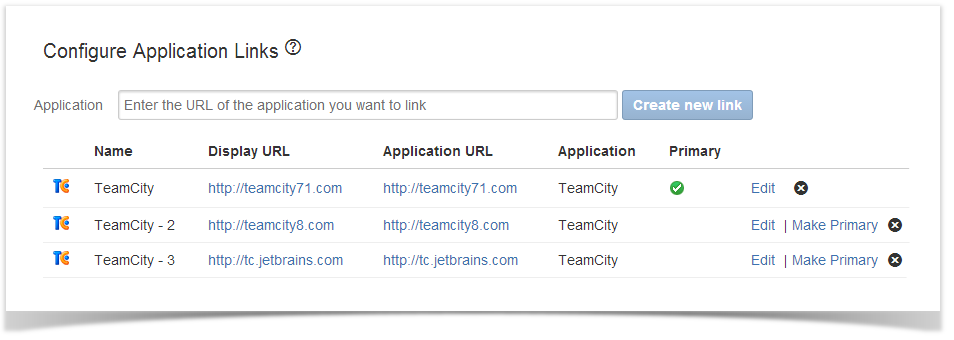
Enterprise customers usually have several TeamCity servers, which data about builds should be available in one place – in JIRA. Now the add-on allows you to view information about builds from multiple TeamCity servers within the associated JIRA issue and see availability of build agents per each server. You can connect as many as needed TeamCity servers to your JIRA just by adding the corresponding application links.
Persistent Data Storage
Some customers may also have TeamCity servers storing millions of builds. This fact affects availability of data in JIRA after its restart or update of the add-on. This can be achieved only through maximally quick data indexation and rapid data access to the requested information. The persistent storage for TeamCity data addresses all these issues and lets you always get quick access and maximal data availability after the scheduled maintenance work.
Indexation Optimization
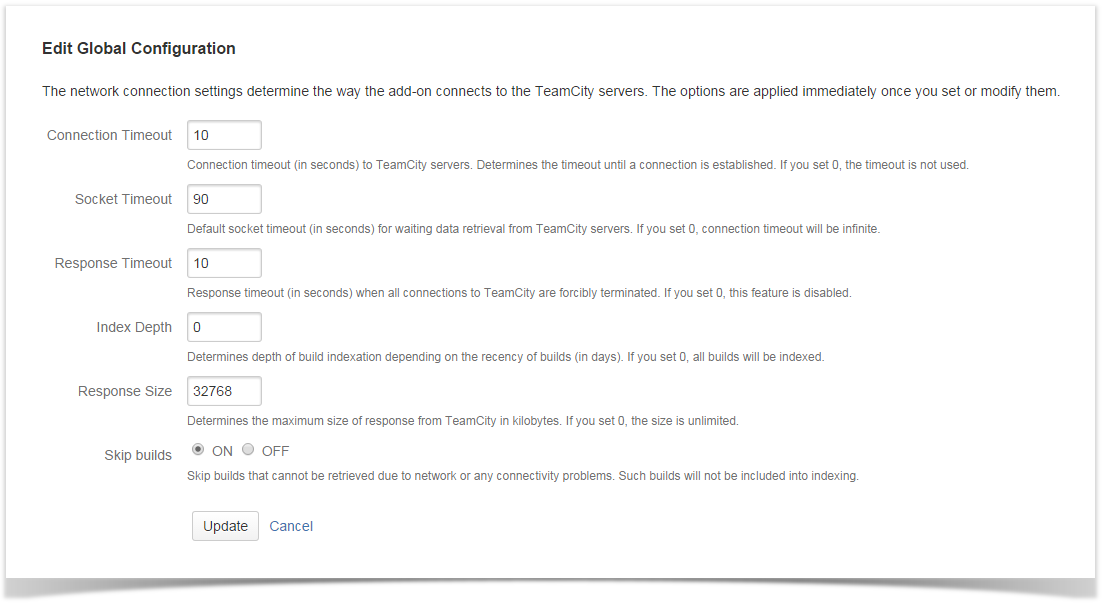
TeamCity servers storing millions of builds can be slow due to large data amounts and can be even inaccessible because of the periodical clean-up. The continuous integration server may also store some abnormal builds with up to 10,000 commits and requests, which comprise two-gigabyte response from TeamCity server during data indexing.
That’s why the add-on has received several options, such as Response Timeout, Socket Timeout, Connection Timeout that allow you to adjust data indexation and speed up the entire process from large TeamCity Servers. The three other options – Index Depth, Response Size and Skip Builds – allow you to limit depth of TeamCity data indexation and better handle abnormal builds with a capability to skip them from the indexing.
Sometimes cool products appear out of the blue. People just look for a tool for solving their everyday tasks and provided they find none they create it from scratch. If they get a good result, they share it with others. This is how JIRA Automation Plugin came into existence. It’s a known fact that some issues in a bug-tracker or issue-tracker of a large company can go unattended and pop up after a while, which can be somewhat frustrating for users who submitted this issue.
This problem drove the Atlassian team to create a tool to prevent such situations. What to do if for a few weeks nobody commented on a bug that is hard to reproduce? How to understand, if it got to a new release or was fixed? How not to forget getting feedback from a user? JIRA Automation Plugin was meant to solve such problems. And it seems it did solve them since it was shared with the community to help other developers with similar issues.
Add-on Functionality
From the start, it was decided to keep the number of features low. However, each feature is quite functional, there’re a lot of thing you can do with them.
The add-on can:
execute some (Cron-based) JQL query and handle the results
add comments to existing issues
perform actions triggered by some events in JIRA
All this can help to do some thing automatically, like easy stuff as closing very old bugs that are not reproduced for a long time and are not important, or something more complicated. For example, when users log their work on a bug labelled as Important, the system can add a comment asking if it is fixed, and in case it is the label can be removed. It’s only a flow used in JIRA and your creativity that can limit you in coming up with tasks that can be done automatically with this add-on.
Not functional requirements
Truly powerful and popular solution should also be easy-to-use and safe. That’s why the list of requirements was expanded with:
easy and fast setting up
audit logging
loop protection (so JIRA don’t go down if user actions triggered an endless loop)
How does it work
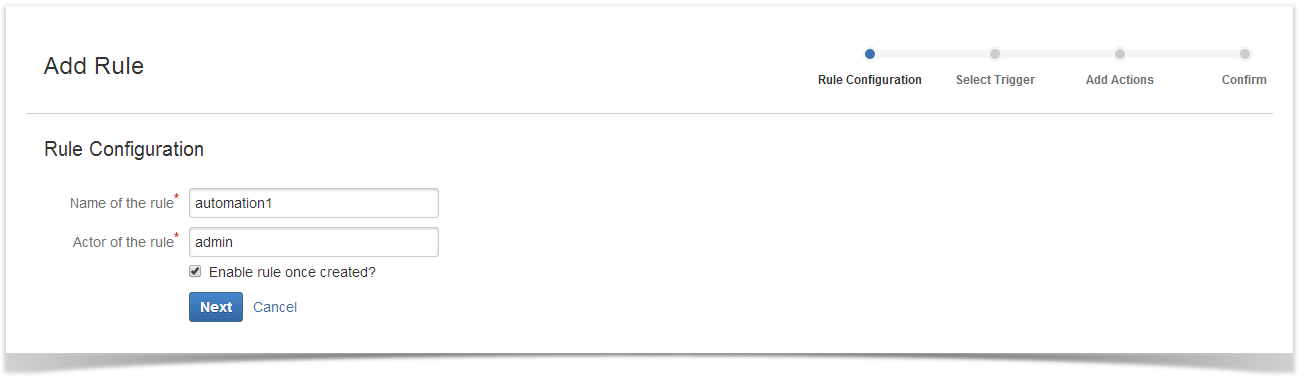
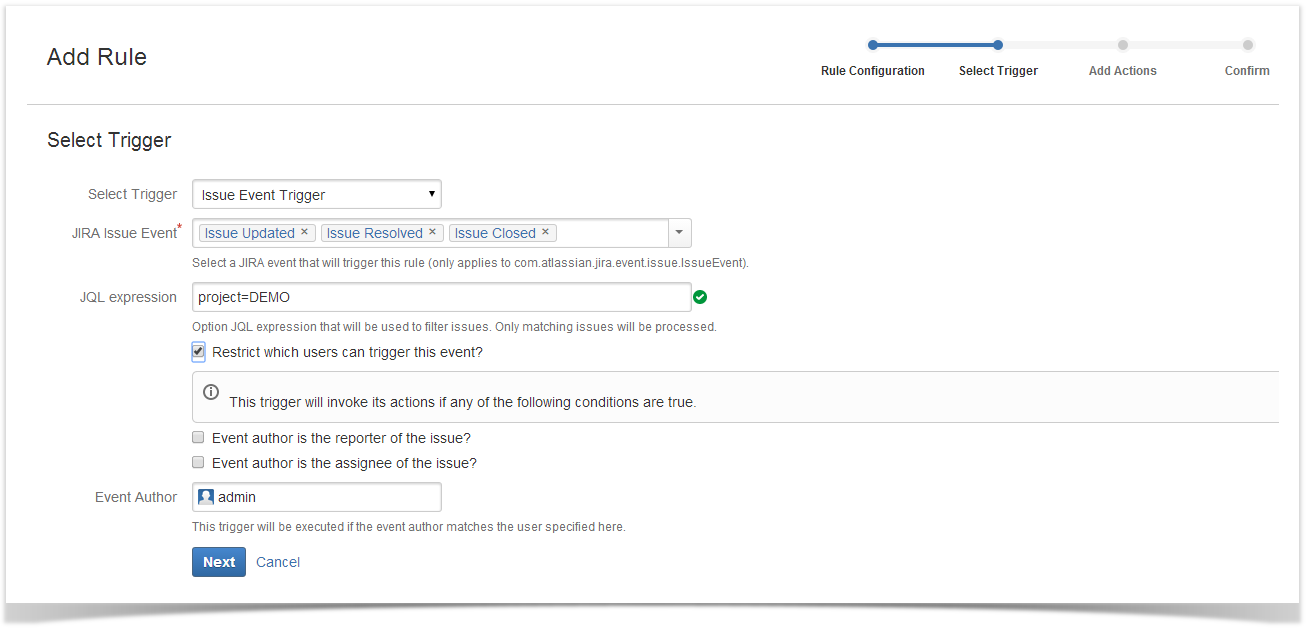
To create an automated task, you need to create and enable at least one rule. The rule is created in 4 steps::
Setting a rule name and user account to work under
You can enable the rule right away.
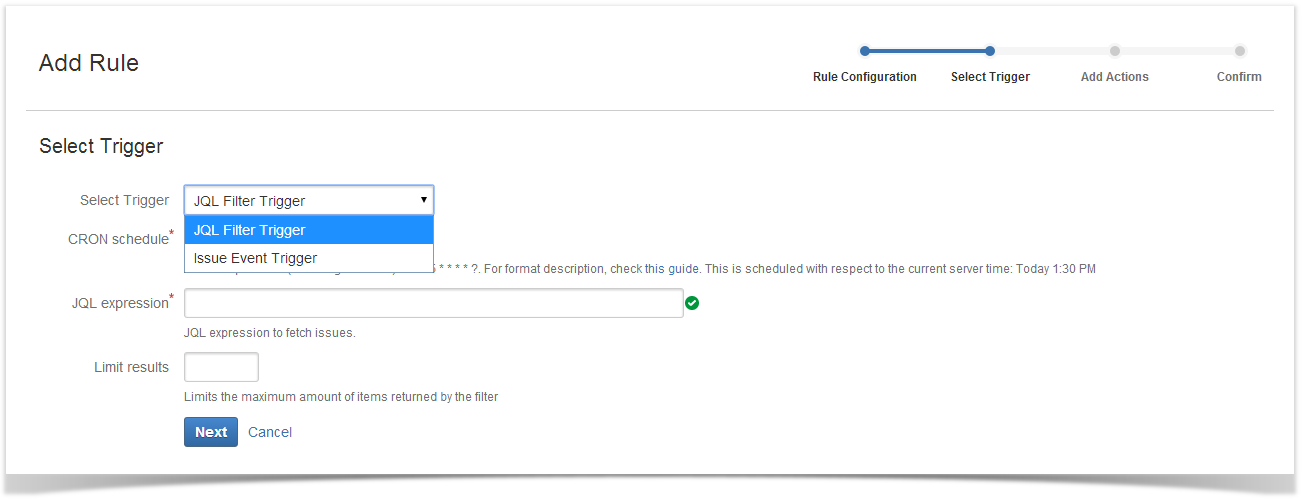
Setting a trigger type
There may be only two types – a JQL expressions and an issue event.
When working with JQL filters, you need to specify a JQL expressin and time of executing this expressions in CRON format. You can also limit the number of results retrieved by the JQL expression.
In case you need to perform some actions triggered by an issue event, you should select these events (can be multiple). If you want, you can limit issues affected by the trigger (reduce their number). Also, you can set a limit for users whose actions can activate the trigger.
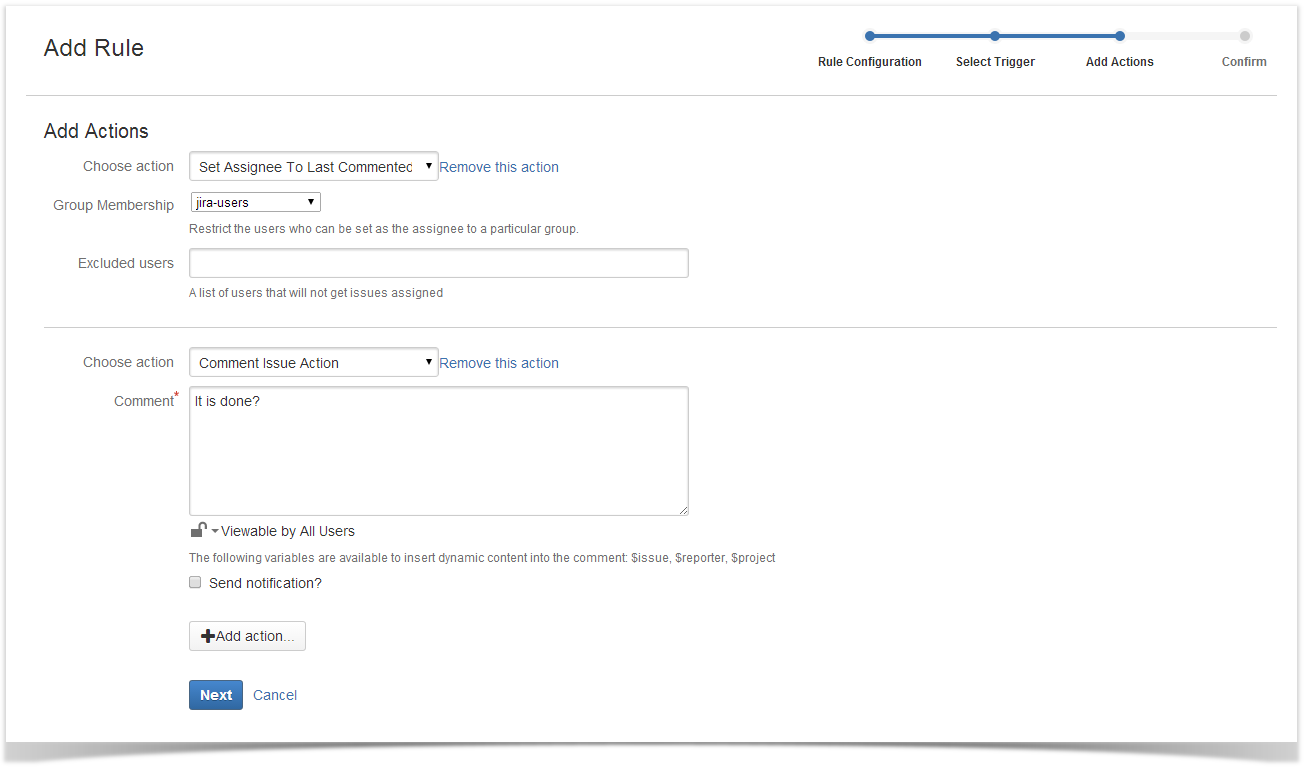
Adding triggered actions
There’re not many actions that can be performed automatically. Mainly, they are changing a responsible person, edit and delete an issue. However, you can add several of these which gives you a big range of possible solutions.
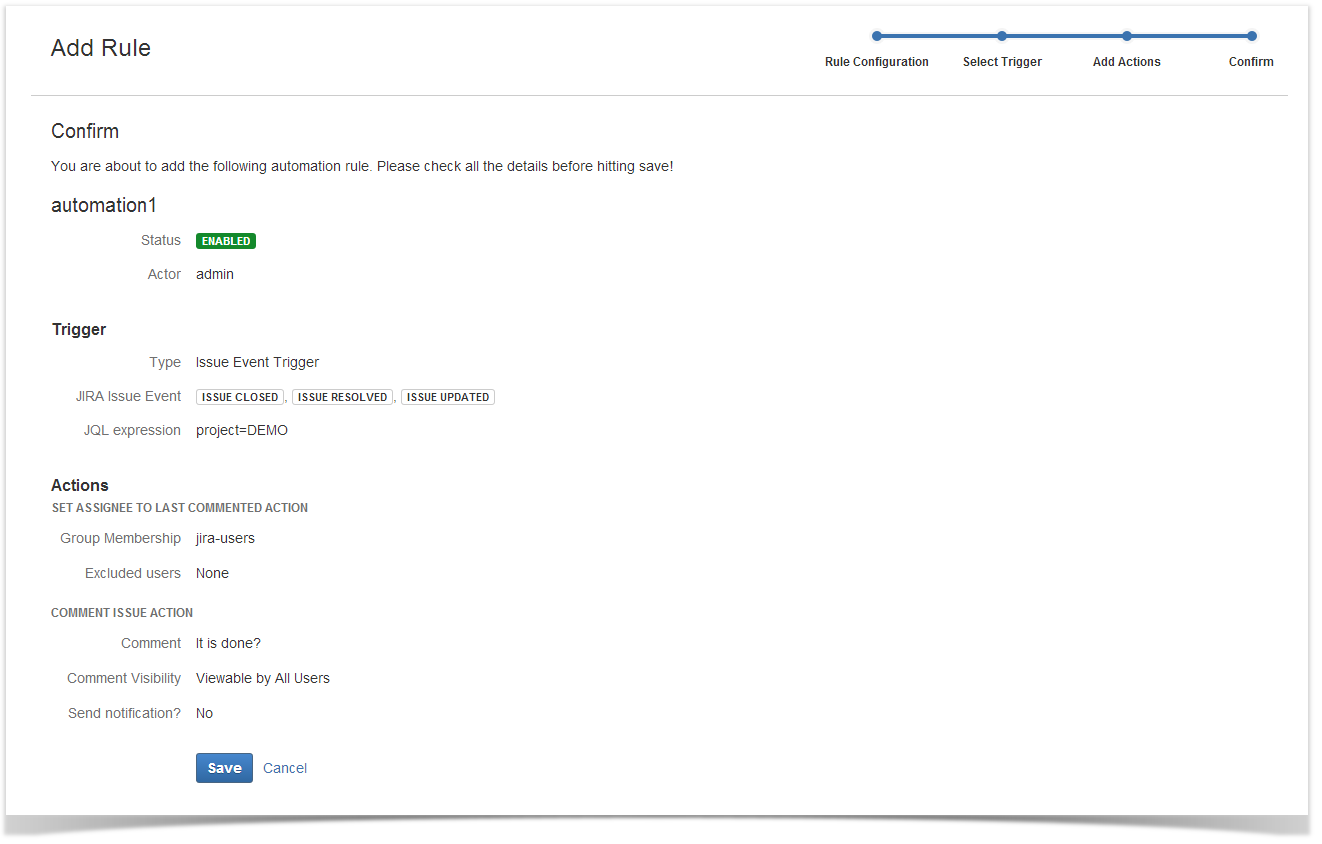
Almost there
All you need to do now is to check if everything is correct and here you go.
OK, one routine process is away. To use the add-on easily, there’re options of rule disabling, editing and copying for you. Of course, you can delete rules. The add-on audits rules actions and has a setting that limits the frequency of performing actions to avoid server overloading. However, this limiting algorithm is obscure and not customizable, you can only enable or disable it.
Conclusion
Atlassian made a pretty handy solution for automatically performing easy actions in JIRA. Although the tool is quite new, it boasts relatively flexible and, more importantly, intuitive settings and is quite good for a first version, however, there’s still room to improve.
It makes sense to use it on large JIRA instances with hundreds and thousands of users. Still it may be useful on smaller instances too.
The main drawback is the lack of evaluating consequences of creating a rule. For example, it would be great to see a warning before enabling the rule like ‘This action will affect a large number of issues (2985). Do you want to continue?’ with the Save and Disable buttons.
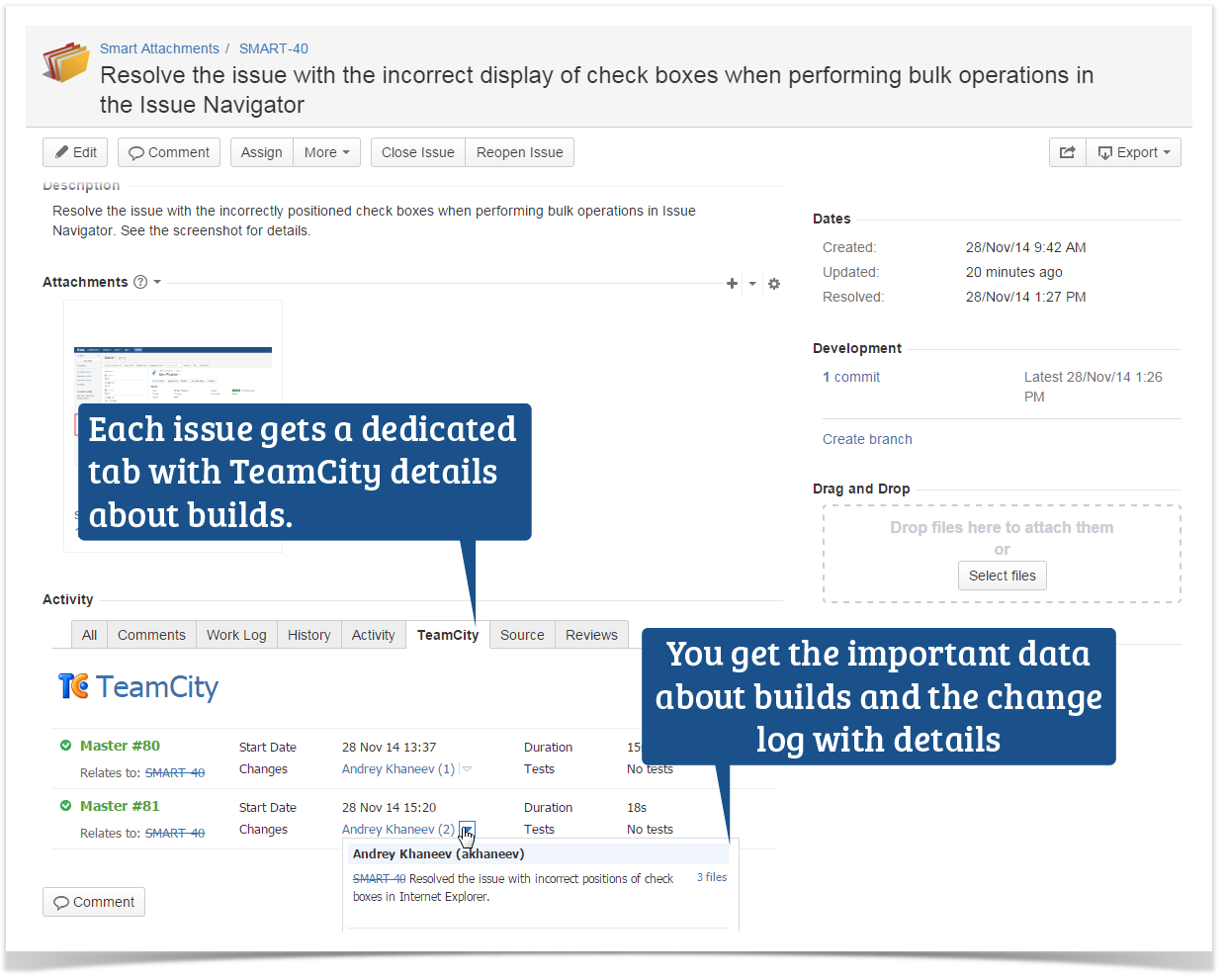
This is how the add-on looks like in real life:
Subscribe for monthly updates on how to get the most out of Atlassian products.
Thank you for signing up
for our newsletter!
You will be the first to know about fresh content, releases,
and special projects.
Stay tuned.
Integrate multiple TeamCity servers with your Jira
April 15, 2014
#Jira
3 min
We are happy to announce that one of the most demanding features for TeamCity Integration for Jira has been added. Now the app supports work with multiple TeamCity servers, so you can easily get data from multiple continuous integration servers for your needs.
You can instantly view complex data about your projects and builds without accessing TeamCity servers. If you have multiple projects, one per TeamCity server, you can view the statuses for each in your Jira. So you needn’t always switch between Jira and your multiple TeamCity servers.
All you need is to add several application links to TeamCity, the rest of the work will be done by the app. It will thoroughly process and index all the available data from each server for you to view in your Jira.
All the information about your project builds and used configurations will always be in your hand. For the details on completed builds, you can instantly proceed to the appropriate TeamCity instance right from Jira. The app treats each TeamCity server individually, so a similar set of data will be available for each instance. If the same issue is mentioned on multiple TeamCity servers, you will see information from several servers in one listing.
So what can you benefit from this?
First, you get a convenient tool for being aware of all progress in your projects.
Second, you can always directly proceed to the right page with details of the build or configuration without long browsing sections of TeamCity.
Third, you can quickly collect data from all your TeamCity servers in your Jira. And the last, you can always track any changes and modified files for each task.
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept All”, you consent to the use of ALL the cookies. However, you may visit "Cookie Settings" to provide a controlled consent.
We use necessary cookies to optimize our site. We’d also like to set performance cookies that help us make improvements by measuring how you use the site.
By clicking “Accept all”, you voluntarily agree to the data processing mentioned.
The cookies collect information in a way that does not directly identify anyone. For more information on how these cookies work please see our ‘Cookies policy’.
Necessary cookies are used for activities that are strictly necessary to operate or deliver the service you requested from us and, therefore, do not require you to consent. They enable core functionality such as security, network management, and accessibility.
Performance cookies enable improved functionality and personalization and help us measure traffic and analyze your behavior with the goal of improving our service. This means that our services may not work properly if they are disabled.